
Text Prediction - Heterogeneous Data Types¶
In your applications, your text data may be mixed with other common data
types like numerical data and categorical data (which are commonly found
in tabular data). The TextPrediction task in AutoGluon can train a
single neural network that jointly operates on multiple feature types,
including text, categorical, and numerical columns. Here we’ll again use
the Semantic Textual
Similarity
dataset to illustrate this functionality.
import numpy as np
import warnings
warnings.filterwarnings('ignore')
np.random.seed(123)
Load Data and Train Model¶
from autogluon.core.utils.loaders import load_pd
train_data = load_pd.load('https://autogluon-text.s3-accelerate.amazonaws.com/glue/sts/train.parquet')
dev_data = load_pd.load('https://autogluon-text.s3-accelerate.amazonaws.com/glue/sts/dev.parquet')
train_data.head(10)
| sentence1 | sentence2 | genre | score | |
|---|---|---|---|---|
| 0 | A plane is taking off. | An air plane is taking off. | main-captions | 5.00 |
| 1 | A man is playing a large flute. | A man is playing a flute. | main-captions | 3.80 |
| 2 | A man is spreading shreded cheese on a pizza. | A man is spreading shredded cheese on an uncoo... | main-captions | 3.80 |
| 3 | Three men are playing chess. | Two men are playing chess. | main-captions | 2.60 |
| 4 | A man is playing the cello. | A man seated is playing the cello. | main-captions | 4.25 |
| 5 | Some men are fighting. | Two men are fighting. | main-captions | 4.25 |
| 6 | A man is smoking. | A man is skating. | main-captions | 0.50 |
| 7 | The man is playing the piano. | The man is playing the guitar. | main-captions | 1.60 |
| 8 | A man is playing on a guitar and singing. | A woman is playing an acoustic guitar and sing... | main-captions | 2.20 |
| 9 | A person is throwing a cat on to the ceiling. | A person throws a cat on the ceiling. | main-captions | 5.00 |
Note the STS dataset contains two text fields: sentence1 and
sentence2, one categorical field: genre, and one numerical field
score. Let’s try to predict the score based on the other
features: sentence1, sentence2, genre.
import autogluon.core as ag
from autogluon.text import TextPrediction as task
predictor_score = task.fit(train_data, label='score',
time_limits=60, ngpus_per_trial=1, seed=123,
output_directory='./ag_sts_mixed_score')
2021-02-23 19:31:54,207 - autogluon.text.text_prediction.text_prediction - INFO - All Logs will be saved to ./ag_sts_mixed_score/ag_text_prediction.log
INFO:autogluon.text.text_prediction.text_prediction:All Logs will be saved to ./ag_sts_mixed_score/ag_text_prediction.log
2021-02-23 19:31:54,244 - autogluon.text.text_prediction.text_prediction - INFO - Train Dataset:
INFO:autogluon.text.text_prediction.text_prediction:Train Dataset:
2021-02-23 19:31:54,244 - autogluon.text.text_prediction.text_prediction - INFO - Columns:
- Text(
name="sentence1"
#total/missing=4599/0
length, min/avg/max=16/57.62056968906284/367
)
- Text(
name="sentence2"
#total/missing=4599/0
length, min/avg/max=15/57.47532072189606/311
)
- Categorical(
name="genre"
#total/missing=4599/0
num_class (total/non_special)=4/3
categories=['main-captions', 'main-forums', 'main-news']
freq=[1608, 366, 2625]
)
- Numerical(
name="score"
#total/missing=4599/0
shape=()
)
INFO:autogluon.text.text_prediction.text_prediction:Columns:
- Text(
name="sentence1"
#total/missing=4599/0
length, min/avg/max=16/57.62056968906284/367
)
- Text(
name="sentence2"
#total/missing=4599/0
length, min/avg/max=15/57.47532072189606/311
)
- Categorical(
name="genre"
#total/missing=4599/0
num_class (total/non_special)=4/3
categories=['main-captions', 'main-forums', 'main-news']
freq=[1608, 366, 2625]
)
- Numerical(
name="score"
#total/missing=4599/0
shape=()
)
2021-02-23 19:31:54,246 - autogluon.text.text_prediction.text_prediction - INFO - Tuning Dataset:
INFO:autogluon.text.text_prediction.text_prediction:Tuning Dataset:
2021-02-23 19:31:54,247 - autogluon.text.text_prediction.text_prediction - INFO - Columns:
- Text(
name="sentence1"
#total/missing=1150/0
length, min/avg/max=16/58.06/315
)
- Text(
name="sentence2"
#total/missing=1150/0
length, min/avg/max=15/57.76173913043478/256
)
- Categorical(
name="genre"
#total/missing=1150/0
num_class (total/non_special)=4/3
categories=['main-captions', 'main-forums', 'main-news']
freq=[392, 84, 674]
)
- Numerical(
name="score"
#total/missing=1150/0
shape=()
)
INFO:autogluon.text.text_prediction.text_prediction:Columns:
- Text(
name="sentence1"
#total/missing=1150/0
length, min/avg/max=16/58.06/315
)
- Text(
name="sentence2"
#total/missing=1150/0
length, min/avg/max=15/57.76173913043478/256
)
- Categorical(
name="genre"
#total/missing=1150/0
num_class (total/non_special)=4/3
categories=['main-captions', 'main-forums', 'main-news']
freq=[392, 84, 674]
)
- Numerical(
name="score"
#total/missing=1150/0
shape=()
)
WARNING:autogluon.core.utils.multiprocessing_utils:WARNING: changing multiprocessing start method to forkserver
2021-02-23 19:31:54,254 - autogluon.text.text_prediction.text_prediction - INFO - All Logs will be saved to ./ag_sts_mixed_score/main.log
INFO:autogluon.text.text_prediction.text_prediction:All Logs will be saved to ./ag_sts_mixed_score/main.log
0%| | 0/3 [00:00<?, ?it/s]
2021-02-23 19:32:54,845 - autogluon.text.text_prediction.text_prediction - INFO - Results=
INFO:autogluon.text.text_prediction.text_prediction:Results=
2021-02-23 19:32:54,846 - autogluon.text.text_prediction.text_prediction - INFO - Best_config={'search_space▁optimization.lr': 5e-05}
INFO:autogluon.text.text_prediction.text_prediction:Best_config={'search_space▁optimization.lr': 5e-05}
(task:0) 2021-02-23 19:31:57,168 - root - INFO - All Logs will be saved to /var/lib/jenkins/workspace/workspace/autogluon-tutorial-text-v3/docs/_build/eval/tutorials/text_prediction/ag_sts_mixed_score/task0/training.log
2021-02-23 19:31:57,168 - root - INFO - learning:
early_stopping_patience: 10
log_metrics: auto
stop_metric: auto
valid_ratio: 0.15
misc:
exp_dir: /var/lib/jenkins/workspace/workspace/autogluon-tutorial-text-v3/docs/_build/eval/tutorials/text_prediction/ag_sts_mixed_score/task0
seed: 123
model:
backbone:
name: google_electra_small
network:
agg_net:
activation: tanh
agg_type: concat
data_dropout: False
dropout: 0.1
feature_proj_num_layers: -1
initializer:
bias: ['zeros']
weight: ['xavier', 'uniform', 'avg', 3.0]
mid_units: 256
norm_eps: 1e-05
normalization: layer_norm
out_proj_num_layers: 0
categorical_net:
activation: leaky
data_dropout: False
dropout: 0.1
emb_units: 32
initializer:
bias: ['zeros']
embed: ['xavier', 'gaussian', 'in', 1.0]
weight: ['xavier', 'uniform', 'avg', 3.0]
mid_units: 64
norm_eps: 1e-05
normalization: layer_norm
num_layers: 1
feature_units: -1
initializer:
bias: ['zeros']
weight: ['truncnorm', 0, 0.02]
numerical_net:
activation: leaky
data_dropout: False
dropout: 0.1
initializer:
bias: ['zeros']
weight: ['xavier', 'uniform', 'avg', 3.0]
input_centering: False
mid_units: 128
norm_eps: 1e-05
normalization: layer_norm
num_layers: 1
text_net:
pool_type: cls
use_segment_id: True
preprocess:
max_length: 128
merge_text: True
optimization:
batch_size: 32
begin_lr: 0.0
final_lr: 0.0
layerwise_lr_decay: 0.8
log_frequency: 0.1
lr: 5e-05
lr_scheduler: triangular
max_grad_norm: 1.0
model_average: 5
num_train_epochs: 4
optimizer: adamw
optimizer_params: [('beta1', 0.9), ('beta2', 0.999), ('epsilon', 1e-06), ('correct_bias', False)]
per_device_batch_size: 16
val_batch_size_mult: 2
valid_frequency: 0.1
warmup_portion: 0.1
wd: 0.01
version: 1
2021-02-23 19:31:57,322 - root - INFO - Process training set...
2021-02-23 19:32:00,799 - root - INFO - Done!
2021-02-23 19:32:00,800 - root - INFO - Process dev set...
2021-02-23 19:32:03,724 - root - INFO - Done!
2021-02-23 19:32:09,070 - root - INFO - #Total Params/Fixed Params=13502465/0
2021-02-23 19:32:09,085 - root - INFO - Using gradient accumulation. Global batch size = 32
2021-02-23 19:32:11,815 - root - INFO - [Iter 15/576, Epoch 0] train loss=5.6507e+00, gnorm=4.9893e+01, lr=1.3158e-05, #samples processed=720, #sample per second=268.13
2021-02-23 19:32:12,916 - root - INFO - [Iter 15/576, Epoch 0] valid mean_squared_error=2.6513e+00, root_mean_squared_error=1.6283e+00, mean_absolute_error=1.3947e+00, time spent=1.017s, total_time=0.06min
2021-02-23 19:32:14,682 - root - INFO - [Iter 30/576, Epoch 0] train loss=1.6084e+00, gnorm=2.6184e+01, lr=2.6316e-05, #samples processed=720, #sample per second=251.15
2021-02-23 19:32:15,845 - root - INFO - [Iter 30/576, Epoch 0] valid mean_squared_error=1.8960e+00, root_mean_squared_error=1.3769e+00, mean_absolute_error=1.1792e+00, time spent=1.015s, total_time=0.11min
2021-02-23 19:32:17,629 - root - INFO - [Iter 45/576, Epoch 0] train loss=1.2543e+00, gnorm=1.2617e+01, lr=3.9474e-05, #samples processed=720, #sample per second=244.37
2021-02-23 19:32:18,764 - root - INFO - [Iter 45/576, Epoch 0] valid mean_squared_error=1.2434e+00, root_mean_squared_error=1.1151e+00, mean_absolute_error=9.3495e-01, time spent=1.012s, total_time=0.16min
2021-02-23 19:32:20,599 - root - INFO - [Iter 60/576, Epoch 0] train loss=8.1263e-01, gnorm=3.2290e+01, lr=4.9711e-05, #samples processed=720, #sample per second=242.40
2021-02-23 19:32:21,791 - root - INFO - [Iter 60/576, Epoch 0] valid mean_squared_error=1.2278e+00, root_mean_squared_error=1.1081e+00, mean_absolute_error=8.6170e-01, time spent=1.017s, total_time=0.21min
2021-02-23 19:32:23,524 - root - INFO - [Iter 75/576, Epoch 0] train loss=7.2429e-01, gnorm=1.4131e+01, lr=4.8266e-05, #samples processed=720, #sample per second=246.17
2021-02-23 19:32:24,663 - root - INFO - [Iter 75/576, Epoch 0] valid mean_squared_error=8.4852e-01, root_mean_squared_error=9.2115e-01, mean_absolute_error=7.2925e-01, time spent=1.021s, total_time=0.26min
2021-02-23 19:32:26,444 - root - INFO - [Iter 90/576, Epoch 0] train loss=7.6705e-01, gnorm=2.3642e+01, lr=4.6821e-05, #samples processed=720, #sample per second=246.63
2021-02-23 19:32:27,629 - root - INFO - [Iter 90/576, Epoch 0] valid mean_squared_error=7.8579e-01, root_mean_squared_error=8.8645e-01, mean_absolute_error=6.8949e-01, time spent=1.019s, total_time=0.31min
2021-02-23 19:32:30,156 - root - INFO - [Iter 105/576, Epoch 0] train loss=6.5210e-01, gnorm=1.5208e+01, lr=4.5376e-05, #samples processed=720, #sample per second=193.98
2021-02-23 19:32:31,337 - root - INFO - [Iter 105/576, Epoch 0] valid mean_squared_error=6.4240e-01, root_mean_squared_error=8.0150e-01, mean_absolute_error=6.2913e-01, time spent=1.037s, total_time=0.37min
2021-02-23 19:32:33,413 - root - INFO - [Iter 120/576, Epoch 0] train loss=5.6492e-01, gnorm=2.2154e+01, lr=4.3931e-05, #samples processed=720, #sample per second=221.01
2021-02-23 19:32:34,439 - root - INFO - [Iter 120/576, Epoch 0] valid mean_squared_error=7.0424e-01, root_mean_squared_error=8.3919e-01, mean_absolute_error=6.4381e-01, time spent=1.025s, total_time=0.42min
2021-02-23 19:32:36,351 - root - INFO - [Iter 135/576, Epoch 0] train loss=6.8248e-01, gnorm=2.2652e+01, lr=4.2486e-05, #samples processed=720, #sample per second=245.09
2021-02-23 19:32:37,515 - root - INFO - [Iter 135/576, Epoch 0] valid mean_squared_error=6.1367e-01, root_mean_squared_error=7.8337e-01, mean_absolute_error=6.1023e-01, time spent=1.028s, total_time=0.47min
2021-02-23 19:32:39,224 - root - INFO - [Iter 150/576, Epoch 1] train loss=5.9588e-01, gnorm=3.0917e+01, lr=4.1040e-05, #samples processed=711, #sample per second=247.52
2021-02-23 19:32:40,257 - root - INFO - [Iter 150/576, Epoch 1] valid mean_squared_error=6.9121e-01, root_mean_squared_error=8.3139e-01, mean_absolute_error=6.3975e-01, time spent=1.033s, total_time=0.52min
2021-02-23 19:32:42,046 - root - INFO - [Iter 165/576, Epoch 1] train loss=5.2718e-01, gnorm=1.4718e+01, lr=3.9595e-05, #samples processed=720, #sample per second=255.14
2021-02-23 19:32:43,081 - root - INFO - [Iter 165/576, Epoch 1] valid mean_squared_error=6.1859e-01, root_mean_squared_error=7.8651e-01, mean_absolute_error=6.0163e-01, time spent=1.034s, total_time=0.57min
2021-02-23 19:32:44,791 - root - INFO - [Iter 180/576, Epoch 1] train loss=5.3662e-01, gnorm=1.3640e+01, lr=3.8150e-05, #samples processed=720, #sample per second=262.46
2021-02-23 19:32:45,824 - root - INFO - [Iter 180/576, Epoch 1] valid mean_squared_error=6.2726e-01, root_mean_squared_error=7.9200e-01, mean_absolute_error=6.0881e-01, time spent=1.033s, total_time=0.61min
2021-02-23 19:32:47,567 - root - INFO - [Iter 195/576, Epoch 1] train loss=5.4052e-01, gnorm=1.9617e+01, lr=3.6705e-05, #samples processed=720, #sample per second=259.34
2021-02-23 19:32:48,738 - root - INFO - [Iter 195/576, Epoch 1] valid mean_squared_error=5.9721e-01, root_mean_squared_error=7.7279e-01, mean_absolute_error=5.9233e-01, time spent=1.034s, total_time=0.66min
2021-02-23 19:32:50,386 - root - INFO - [Iter 210/576, Epoch 1] train loss=5.2052e-01, gnorm=1.6429e+01, lr=3.5260e-05, #samples processed=720, #sample per second=255.45
2021-02-23 19:32:51,588 - root - INFO - [Iter 210/576, Epoch 1] valid mean_squared_error=5.9169e-01, root_mean_squared_error=7.6921e-01, mean_absolute_error=5.8782e-01, time spent=1.035s, total_time=0.71min
2021-02-23 19:32:53,272 - root - INFO - [Iter 225/576, Epoch 1] train loss=4.7563e-01, gnorm=1.9520e+01, lr=3.3815e-05, #samples processed=720, #sample per second=249.52
2021-02-23 19:32:54,310 - root - INFO - [Iter 225/576, Epoch 1] valid mean_squared_error=5.9243e-01, root_mean_squared_error=7.6969e-01, mean_absolute_error=5.8187e-01, time spent=1.037s, total_time=0.75min
score = predictor_score.evaluate(dev_data, metrics='spearmanr')
print('Spearman Correlation=', score['spearmanr'])
/var/lib/jenkins/workspace/workspace/autogluon-tutorial-text-v3/venv/lib/python3.8/site-packages/mxnet/gluon/block.py:995: UserWarning: The 3-th input to HybridBlock is not used by any computation. Is this intended?
self._build_cache(*args)
Spearman Correlation= 0.8481924386852326
We can also train a model that predicts the genre using the other columns as features.
predictor_genre = task.fit(train_data, label='genre',
time_limits=60, ngpus_per_trial=1, seed=123,
output_directory='./ag_sts_mixed_genre')
2021-02-23 19:33:04,236 - autogluon.text.text_prediction.text_prediction - INFO - All Logs will be saved to ./ag_sts_mixed_genre/ag_text_prediction.log
INFO:autogluon.text.text_prediction.text_prediction:All Logs will be saved to ./ag_sts_mixed_genre/ag_text_prediction.log
2021-02-23 19:33:04,272 - autogluon.text.text_prediction.text_prediction - INFO - Train Dataset:
INFO:autogluon.text.text_prediction.text_prediction:Train Dataset:
2021-02-23 19:33:04,273 - autogluon.text.text_prediction.text_prediction - INFO - Columns:
- Text(
name="sentence1"
#total/missing=4599/0
length, min/avg/max=16/57.9191128506197/367
)
- Text(
name="sentence2"
#total/missing=4599/0
length, min/avg/max=15/57.6544901065449/311
)
- Categorical(
name="genre"
#total/missing=4599/0
num_class (total/non_special)=3/3
categories=['main-captions', 'main-forums', 'main-news']
freq=[1629, 355, 2615]
)
- Numerical(
name="score"
#total/missing=4599/0
shape=()
)
INFO:autogluon.text.text_prediction.text_prediction:Columns:
- Text(
name="sentence1"
#total/missing=4599/0
length, min/avg/max=16/57.9191128506197/367
)
- Text(
name="sentence2"
#total/missing=4599/0
length, min/avg/max=15/57.6544901065449/311
)
- Categorical(
name="genre"
#total/missing=4599/0
num_class (total/non_special)=3/3
categories=['main-captions', 'main-forums', 'main-news']
freq=[1629, 355, 2615]
)
- Numerical(
name="score"
#total/missing=4599/0
shape=()
)
2021-02-23 19:33:04,274 - autogluon.text.text_prediction.text_prediction - INFO - Tuning Dataset:
INFO:autogluon.text.text_prediction.text_prediction:Tuning Dataset:
2021-02-23 19:33:04,275 - autogluon.text.text_prediction.text_prediction - INFO - Columns:
- Text(
name="sentence1"
#total/missing=1150/0
length, min/avg/max=17/56.86608695652174/227
)
- Text(
name="sentence2"
#total/missing=1150/0
length, min/avg/max=16/57.04521739130435/212
)
- Categorical(
name="genre"
#total/missing=1150/0
num_class (total/non_special)=3/3
categories=['main-captions', 'main-forums', 'main-news']
freq=[371, 95, 684]
)
- Numerical(
name="score"
#total/missing=1150/0
shape=()
)
INFO:autogluon.text.text_prediction.text_prediction:Columns:
- Text(
name="sentence1"
#total/missing=1150/0
length, min/avg/max=17/56.86608695652174/227
)
- Text(
name="sentence2"
#total/missing=1150/0
length, min/avg/max=16/57.04521739130435/212
)
- Categorical(
name="genre"
#total/missing=1150/0
num_class (total/non_special)=3/3
categories=['main-captions', 'main-forums', 'main-news']
freq=[371, 95, 684]
)
- Numerical(
name="score"
#total/missing=1150/0
shape=()
)
2021-02-23 19:33:04,277 - autogluon.text.text_prediction.text_prediction - INFO - All Logs will be saved to ./ag_sts_mixed_genre/main.log
INFO:autogluon.text.text_prediction.text_prediction:All Logs will be saved to ./ag_sts_mixed_genre/main.log
0%| | 0/3 [00:00<?, ?it/s]
2021-02-23 19:34:06,562 - autogluon.text.text_prediction.text_prediction - INFO - Results=
INFO:autogluon.text.text_prediction.text_prediction:Results=
2021-02-23 19:34:06,563 - autogluon.text.text_prediction.text_prediction - INFO - Best_config={'search_space▁optimization.lr': 5e-05}
INFO:autogluon.text.text_prediction.text_prediction:Best_config={'search_space▁optimization.lr': 5e-05}
(task:1) 2021-02-23 19:33:06,991 - root - INFO - All Logs will be saved to /var/lib/jenkins/workspace/workspace/autogluon-tutorial-text-v3/docs/_build/eval/tutorials/text_prediction/ag_sts_mixed_genre/task1/training.log
2021-02-23 19:33:06,992 - root - INFO - learning:
early_stopping_patience: 10
log_metrics: auto
stop_metric: auto
valid_ratio: 0.15
misc:
exp_dir: /var/lib/jenkins/workspace/workspace/autogluon-tutorial-text-v3/docs/_build/eval/tutorials/text_prediction/ag_sts_mixed_genre/task1
seed: 123
model:
backbone:
name: google_electra_small
network:
agg_net:
activation: tanh
agg_type: concat
data_dropout: False
dropout: 0.1
feature_proj_num_layers: -1
initializer:
bias: ['zeros']
weight: ['xavier', 'uniform', 'avg', 3.0]
mid_units: 256
norm_eps: 1e-05
normalization: layer_norm
out_proj_num_layers: 0
categorical_net:
activation: leaky
data_dropout: False
dropout: 0.1
emb_units: 32
initializer:
bias: ['zeros']
embed: ['xavier', 'gaussian', 'in', 1.0]
weight: ['xavier', 'uniform', 'avg', 3.0]
mid_units: 64
norm_eps: 1e-05
normalization: layer_norm
num_layers: 1
feature_units: -1
initializer:
bias: ['zeros']
weight: ['truncnorm', 0, 0.02]
numerical_net:
activation: leaky
data_dropout: False
dropout: 0.1
initializer:
bias: ['zeros']
weight: ['xavier', 'uniform', 'avg', 3.0]
input_centering: False
mid_units: 128
norm_eps: 1e-05
normalization: layer_norm
num_layers: 1
text_net:
pool_type: cls
use_segment_id: True
preprocess:
max_length: 128
merge_text: True
optimization:
batch_size: 32
begin_lr: 0.0
final_lr: 0.0
layerwise_lr_decay: 0.8
log_frequency: 0.1
lr: 5e-05
lr_scheduler: triangular
max_grad_norm: 1.0
model_average: 5
num_train_epochs: 4
optimizer: adamw
optimizer_params: [('beta1', 0.9), ('beta2', 0.999), ('epsilon', 1e-06), ('correct_bias', False)]
per_device_batch_size: 16
val_batch_size_mult: 2
valid_frequency: 0.1
warmup_portion: 0.1
wd: 0.01
version: 1
2021-02-23 19:33:07,150 - root - INFO - Process training set...
2021-02-23 19:33:10,633 - root - INFO - Done!
2021-02-23 19:33:10,634 - root - INFO - Process dev set...
2021-02-23 19:33:13,459 - root - INFO - Done!
2021-02-23 19:33:18,714 - root - INFO - #Total Params/Fixed Params=13517955/0
2021-02-23 19:33:18,730 - root - INFO - Using gradient accumulation. Global batch size = 32
2021-02-23 19:33:21,589 - root - INFO - [Iter 15/576, Epoch 0] train loss=7.1142e-01, gnorm=4.4812e+00, lr=1.3158e-05, #samples processed=720, #sample per second=255.39
2021-02-23 19:33:22,683 - root - INFO - [Iter 15/576, Epoch 0] valid accuracy=8.6783e-01, log_loss=6.1542e-01, time spent=1.011s, total_time=0.07min
2021-02-23 19:33:24,712 - root - INFO - [Iter 30/576, Epoch 0] train loss=3.4911e-01, gnorm=2.2116e+00, lr=2.6316e-05, #samples processed=720, #sample per second=230.62
2021-02-23 19:33:25,849 - root - INFO - [Iter 30/576, Epoch 0] valid accuracy=9.1304e-01, log_loss=2.4666e-01, time spent=0.999s, total_time=0.12min
2021-02-23 19:33:27,508 - root - INFO - [Iter 45/576, Epoch 0] train loss=8.7680e-02, gnorm=7.6365e-01, lr=3.9474e-05, #samples processed=720, #sample per second=257.53
2021-02-23 19:33:28,669 - root - INFO - [Iter 45/576, Epoch 0] valid accuracy=9.4174e-01, log_loss=1.2933e-01, time spent=1.003s, total_time=0.16min
2021-02-23 19:33:30,485 - root - INFO - [Iter 60/576, Epoch 0] train loss=7.8471e-02, gnorm=5.4929e+00, lr=4.9711e-05, #samples processed=720, #sample per second=241.88
2021-02-23 19:33:31,635 - root - INFO - [Iter 60/576, Epoch 0] valid accuracy=9.8174e-01, log_loss=4.4302e-02, time spent=0.999s, total_time=0.21min
2021-02-23 19:33:33,299 - root - INFO - [Iter 75/576, Epoch 0] train loss=1.8767e-02, gnorm=1.5032e+00, lr=4.8266e-05, #samples processed=720, #sample per second=255.88
2021-02-23 19:33:34,461 - root - INFO - [Iter 75/576, Epoch 0] valid accuracy=9.8261e-01, log_loss=5.1691e-02, time spent=1.009s, total_time=0.26min
2021-02-23 19:33:36,819 - root - INFO - [Iter 90/576, Epoch 0] train loss=2.3784e-02, gnorm=3.2057e+00, lr=4.6821e-05, #samples processed=720, #sample per second=204.62
2021-02-23 19:33:38,018 - root - INFO - [Iter 90/576, Epoch 0] valid accuracy=9.8957e-01, log_loss=3.7888e-02, time spent=1.029s, total_time=0.32min
2021-02-23 19:33:40,062 - root - INFO - [Iter 105/576, Epoch 0] train loss=8.9034e-03, gnorm=1.0963e+00, lr=4.5376e-05, #samples processed=720, #sample per second=222.04
2021-02-23 19:33:41,242 - root - INFO - [Iter 105/576, Epoch 0] valid accuracy=9.9043e-01, log_loss=3.9366e-02, time spent=1.006s, total_time=0.37min
2021-02-23 19:33:42,998 - root - INFO - [Iter 120/576, Epoch 0] train loss=1.7328e-02, gnorm=8.9687e+00, lr=4.3931e-05, #samples processed=720, #sample per second=245.27
2021-02-23 19:33:44,182 - root - INFO - [Iter 120/576, Epoch 0] valid accuracy=9.9304e-01, log_loss=3.5286e-02, time spent=1.011s, total_time=0.42min
2021-02-23 19:33:46,132 - root - INFO - [Iter 135/576, Epoch 0] train loss=1.2440e-02, gnorm=6.3627e-01, lr=4.2486e-05, #samples processed=720, #sample per second=229.73
2021-02-23 19:33:47,147 - root - INFO - [Iter 135/576, Epoch 0] valid accuracy=9.9043e-01, log_loss=3.5193e-02, time spent=1.015s, total_time=0.47min
2021-02-23 19:33:49,716 - root - INFO - [Iter 150/576, Epoch 1] train loss=4.8044e-02, gnorm=9.9780e+00, lr=4.1040e-05, #samples processed=711, #sample per second=198.40
2021-02-23 19:33:50,742 - root - INFO - [Iter 150/576, Epoch 1] valid accuracy=9.9130e-01, log_loss=3.3006e-02, time spent=1.026s, total_time=0.53min
2021-02-23 19:33:52,617 - root - INFO - [Iter 165/576, Epoch 1] train loss=1.7028e-02, gnorm=3.4045e-01, lr=3.9595e-05, #samples processed=720, #sample per second=248.15
2021-02-23 19:33:53,768 - root - INFO - [Iter 165/576, Epoch 1] valid accuracy=9.9478e-01, log_loss=3.5829e-02, time spent=1.019s, total_time=0.58min
2021-02-23 19:33:55,554 - root - INFO - [Iter 180/576, Epoch 1] train loss=2.8994e-02, gnorm=4.5026e-02, lr=3.8150e-05, #samples processed=720, #sample per second=245.16
2021-02-23 19:33:56,580 - root - INFO - [Iter 180/576, Epoch 1] valid accuracy=9.9304e-01, log_loss=3.4953e-02, time spent=1.025s, total_time=0.63min
2021-02-23 19:33:58,452 - root - INFO - [Iter 195/576, Epoch 1] train loss=1.2044e-02, gnorm=3.2945e-02, lr=3.6705e-05, #samples processed=720, #sample per second=248.53
2021-02-23 19:33:59,488 - root - INFO - [Iter 195/576, Epoch 1] valid accuracy=9.9304e-01, log_loss=3.1847e-02, time spent=1.036s, total_time=0.68min
2021-02-23 19:34:01,928 - root - INFO - [Iter 210/576, Epoch 1] train loss=3.1744e-02, gnorm=2.2586e+00, lr=3.5260e-05, #samples processed=720, #sample per second=207.13
2021-02-23 19:34:02,968 - root - INFO - [Iter 210/576, Epoch 1] valid accuracy=9.9304e-01, log_loss=3.0680e-02, time spent=1.040s, total_time=0.74min
2021-02-23 19:34:05,108 - root - INFO - [Iter 225/576, Epoch 1] train loss=6.4022e-03, gnorm=1.8780e-01, lr=3.3815e-05, #samples processed=720, #sample per second=226.40
2021-02-23 19:34:06,133 - root - INFO - [Iter 225/576, Epoch 1] valid accuracy=9.9043e-01, log_loss=4.1800e-02, time spent=1.024s, total_time=0.79min
score = predictor_genre.evaluate(dev_data, metrics='acc')
print('Genre-prediction Accuracy = {}%'.format(score['acc'] * 100))
/var/lib/jenkins/workspace/workspace/autogluon-tutorial-text-v3/venv/lib/python3.8/site-packages/mxnet/gluon/block.py:995: UserWarning: The 3-th input to HybridBlock is not used by any computation. Is this intended?
self._build_cache(*args)
Genre-prediction Accuracy = 90.33333333333333%
What’s happening inside?¶
Internally, we use different networks to encode the text columns, categorical columns, and numerical columns. The features generated by individual networks are aggregated by a late-fusion aggregator. The aggregator can output both the logits or score predictions. The architecture can be illustrated as follows:
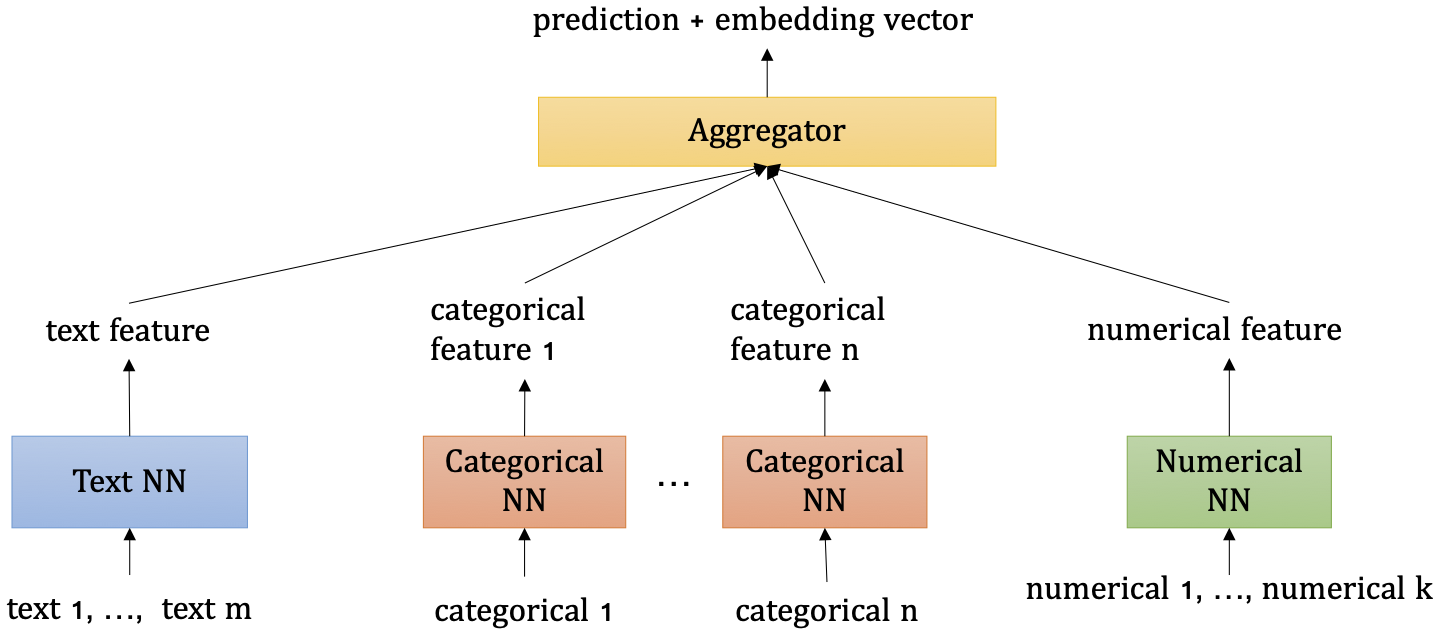
Fig. 1 Neural Network Architecture in TextPrediction¶